Indexes in MySQL
Indexes in MySQL (Mysql indexes) are a great tool for optimizing SQL queries. To understand how they work, let's look at working with data without them.
1 — Reading data from the disk
There is no such thing as a file on a hard disk. There is a concept of a block. One file usually takes up several blocks. Each block knows which block comes after it. The file is divided into chunks and each chunk is stored in an empty block.
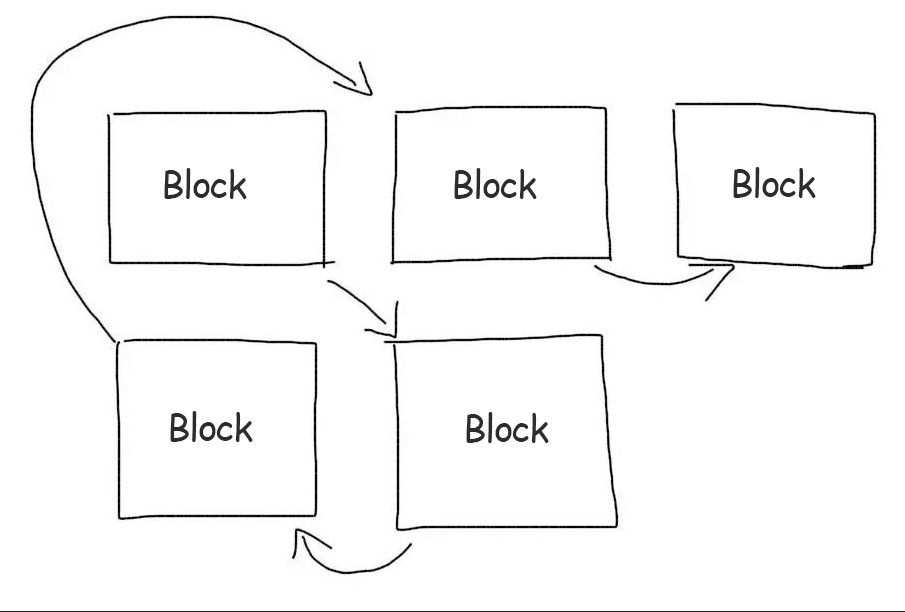
When reading a file, we go through all blocks one by one and assemble the file from pieces. Blocks of the same file can be scattered over the disk (fragmentation). Then reading the file will slow down, because we need to jump over different parts of the disk. When SSD disks are used, this delay is almost imperceptible.
When we are looking for something inside the file, we will need to go through all the blocks in which the file is saved. If the file is very large, the number of blocks will be significant. The need to jump from block to block, which may be in different places, will greatly slow down the search for data.
2 — Search data in MySQL
MySQL tables are normal files. Let's run a query like this:
SELECT * FROM users WHERE age = 29
MySQL opens the file where the data from the users table is stored. And then it starts going through the whole file to find the necessary records.
Besides, MySQL will compare data in each table row with the value in the query. Suppose we are working with a table that has 10 records. Then MySQL will read all 10 records, compare the column of each of them with the value 29 and select only the appropriate data:

So, there are two problems when reading data:
-
Low file reading speed due to the location of blocks in different parts of the disk (fragmentation).
- A large number of comparison operations to find the necessary data.
3 — Data sorting
Suppose we sorted our 10 entries in descending order. Then, using the binary search algorithm, we could at most select the values we want in 4 operations:

In addition to fewer comparison operations, we would save on reading unnecessary records.
Index is a sorted set of values. In MySQL indexes are always built for some particular column. For example, we could build an index for the age column from the example.
4 — Selecting indexes in MySQL
In the simplest case, an index should be created for those columns that are present in the WHERE condition.
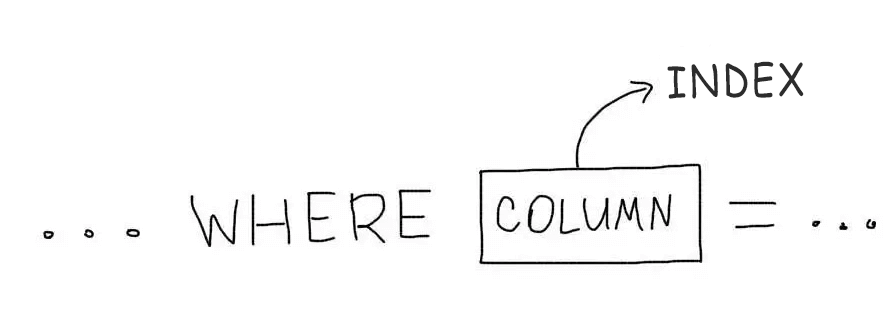
Consider the query from the example:
SELECT * FROM users WHERE age = 29
We need to create an index on the age column:
CREATE INDEX age ON users(age);
After this operation, MySQL will start using the age index to perform similar queries. The index will also be used to sample ranges of values of this column:
SELECT * FROM users WHERE age < 29
Sorting
For queries of this type:
SELECT * FROM users ORDER BY register_date
The same rule applies - we create an index on the column by which the sorting takes place:
CREATE INDEX register_date ON users(register_date);
Indexes storage internals
Let's imagine that our table looks like this:
id | name | age 1 | Den | 29 2 | Alyona | 15 3 | Putin | 89 4 | Petro | 12
After creating an index on the age column, MySQL will save all its values in a sorted form:
age index 12 15 29 89
In addition, the relationship between the value in the index and the record to which that value corresponds will be preserved. Usually a primary key is used for this:
age index and the relation to the records 12: 4 15: 2 29: 1 89: 3
Unique indexes
MySQL supports unique indexes. This is useful for columns whose values must be unique throughout the table. Such indexes improve sampling efficiency for unique values. For example:
SELECT * FROM users WHERE email = '[email protected]';
A unique index must be created for the email column:
CREATE UNIQUE INDEX email ON users(email)
Then, when searching for data, MySQL will stop after finding the first match. In the case of a normal index, another check (of the next value in the index) is sure to be performed.
5 — Composite indexes
MySQL can only use one index for a query (except when MySQL can combine results of multiple index samples). Therefore, for queries that use multiple columns, you must use composite indexes.

Consider such a request:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
We should create a composite index for both columns:
CREATE INDEX age_gender ON users(age, gender);
The structure of a composite index
To use composite indexes correctly, you need to understand their storage structure. Everything works exactly the same way as for a normal index. But for values the values of all incoming columns at once are used. For a table with this data:
id | name | age | gender 1 | Den | 29 | male 2 | Alyona | 15 | female 3 | Putin | 89 | tsar 4 | Petro | 12 | male
the values of the composite index will be as follows:
age_gender 12male 15female 29male 89tsar
This means that the order of columns in the index will play a big role. Usually columns that are used in WHERE conditions should be placed at the beginning of the index. Columns from ORDER BY - at the end.
Search by Range
Let's imagine that our query will not use a comparison, but a range search:
SELECT * FROM users WHERE age <= 29 AND gender = 'male'
Then MySQL will not be able to use the full index because the values of gender will be different for different values of the age column. In this case, the database will try to use part of the index (age only) to perform this query:
age_gender 12male 15female 29male 89tsar
First, all data that match the condition age <= 29 will be filtered out. Then, the search for "male" will be done without using an index.
Sorting
Composite indexes can also be used if sorting is performed:
SELECT * FROM users WHERE gender = 'male' ORDER BY age
In this case we need to create the index in a different order, because sorting (ORDER) takes place after filtering (WHERE):
CREATE INDEX gender_age ON users(gender, age);
This order of columns in the index will allow you to filter by the first part of the index, and then sort the result by the second.
There may be more columns in the index if required:
SELECT * FROM users WHERE gender = 'male' AND country = 'UA' ORDER BY age, register_time
In this case you should create such an index:
CREATE INDEX gender_country_age_register ON users(gender, country, age, register_time);
6 — Using EXPLAIN for index analysis
The EXPLAIN instruction will show data about the use of indexes for a particular query. For example:
mysql> EXPLAIN SELECT * FROM users WHERE email = '[email protected]';

Column key shows the used index. Column possible_keys shows all indexes that can be used for this query. Column rows shows the number of records the database had to read to execute this query (the table has a total of 336 records).
As you can see, no index is used in the example. After creating the index:
mysql> EXPLAIN SELECT * FROM users WHERE email = '[email protected]';

Only one record was read, because an index was used.
Checking the length of composite indexes
Explain will also help you determine if the composite index is used correctly. Let's check the query from the example (with the index on age and gender columns):
mysql> EXPLAIN SELECT * FROM users WHERE age = 29 AND gender = 'male';

The value key_len shows the used length of the index. In our case, 24 bytes is the length of the whole index (5 bytes age + 19 bytes gender).
If we change the exact comparison to a range search, we see that MySQL uses only part of the index:
mysql> EXPLAIN SELECT * FROM users WHERE age <= 29 AND gender = 'male';

This is a signal that the created index is not suitable for this query. If, however, we create the correct index:
mysql> Create index gender_age on users(gender, age); mysql> EXPLAIN SELECT * FROM users WHERE age < 29 and gender = 'male';

In this case MySQL uses the whole gender_age index, because the order of the columns in it allows you to make this selection.
7 — Index selectivity
Back to the query:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
For such a query, you need to create a composite index. But how to choose the right sequence of columns in the index? There are two options:
- age, gender
- gender, age
Both will work. But they will work with different efficiency.
To understand this, consider the uniqueness of each column's values and the number of corresponding entries in the table:
mysql> select age, count(*) from users group by age;
+------+----------+ | age | count(*) | +------+----------+ | 15 | 160 | | 16 | 250 | | ... | | 76 | 210 | | 85 | 230 | +------+----------+ 68 rows in set (0.00 sec)
mysql> select gender, count(*) from users group by gender;
+--------+----------+ | gender | count(*) | +--------+----------+ | female | 8740 | | male | 4500 | +--------+----------+ 2 rows in set (0.00 sec)
This information tells us this:
- Any value in the age column usually contains about 200 records.
- Any value of the gender column is about 6000 records.
If the age column goes first in the index, then MySQL will reduce the number of records to 200 after the first part of the index. Then you just have to select from them. If the column gender will go first, then the number of records will be reduced to 6000 after the first part of the index. I.e. an order of magnitude more than in the case of age.
This means that the age_gender index will work better than gender_age.
Column selectivity is determined by the number of records in the table with the same values. When there are few records with the same value, the selectivity is high. Such columns should be used first in composite indexes.
8 — Primary keys
Primary Key is a special type of index, which is an identifier of records in a table. It is necessarily unique and is specified when creating tables:
CREATE TABLE `users` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `email` varchar(128) NOT NULL, `name` varchar(128) NOT NULL, PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
When using InnoDB tables always define primary keys. If there is no primary key, MySQL will still create a virtual hidden key.
Clustered indexes
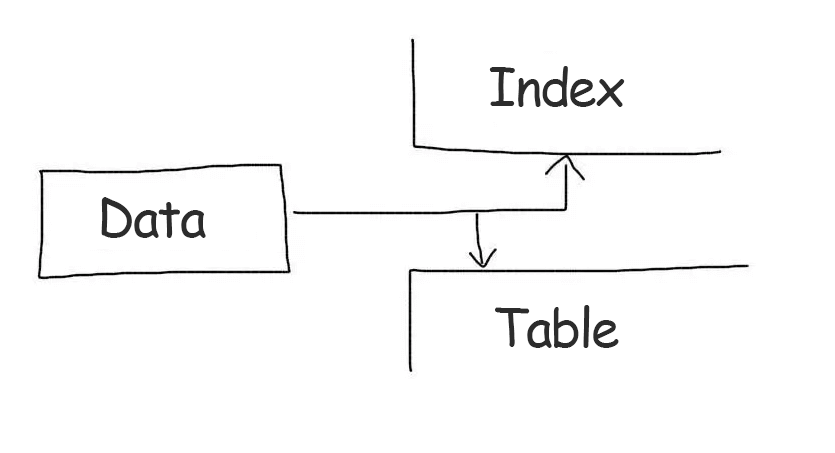
Ordinary indexes are non-clustered indexes. This means that the index itself only stores references to table entries. When working with an index, only the list of records (more precisely, the list of their primary keys) that match the query is defined. After that another query is made to get the data of each record from this list.
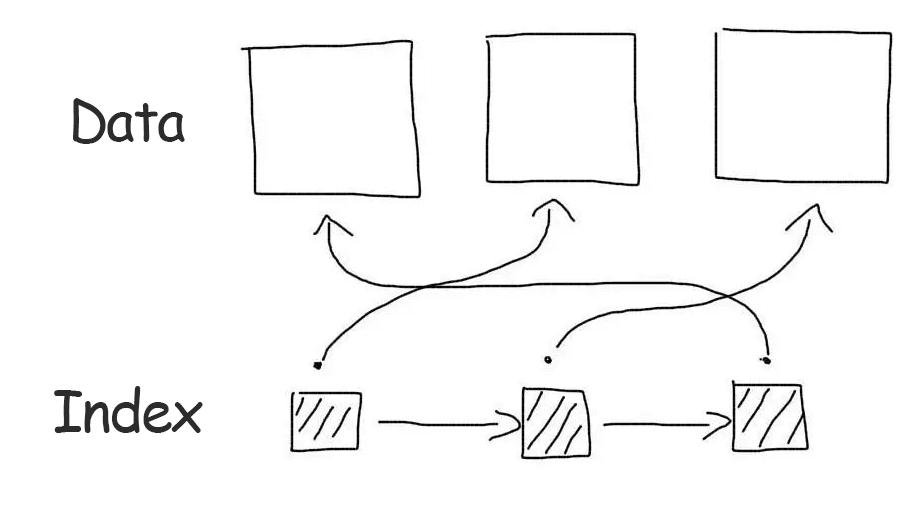
Cluster indexes store the whole record data, not references to them. When working with such an index no additional data reading operation is required.
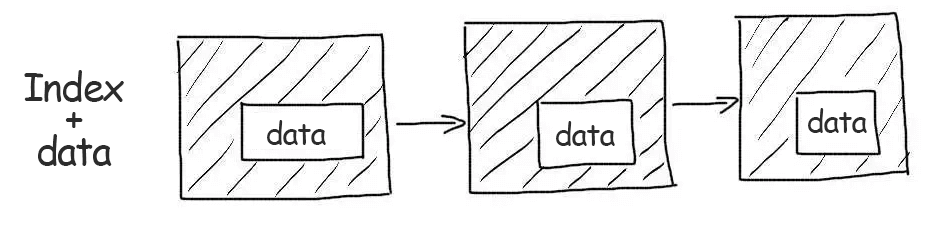
The primary keys of InnoDB tables are clustered. Therefore, they are sampled very efficiently.
Overhead
It is important to remember that indexes involve additional write operations to disk. Every time you update or add data to a table, the data in the index is also written and updated.
Create only necessary indexes to avoid wasting server resources. Control the size of indexes for your tables:
mysql> show table status;
+-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ | Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment | +-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ ... | users | InnoDB | 10 | Compact | 314 | 208 | 65536 | 0 | 16384 | 0 | 355 | 2014-07-11 01:12:17 | NULL | NULL | utf8_general_ci | NULL | | | +-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ 18 rows in set (0.06 sec)
When to create indexes?
-
Indexes should be created as slow queries are detected. The slow log in MySQL will help with this. Queries that run for more than 1 second are the first candidates for optimization.
-
Start creating indexes with the most frequent queries. A query that runs for a second but 1000 times a day does more damage than a 10-second query that runs several times a day.
-
Don't create indexes on tables that have fewer than a few thousand records. For such sizes, the benefit of using an index will be almost imperceptible.
-
Do not create indexes in advance, for example in the development environment. Indexes should be set exclusively for the form and type of load of the running system.
- Remove unused indexes. Use check-unused-keys utility for this.
Most important
Allocate enough time to analyze and organize indexes in MySQL (and other databases). This can take much more time than designing a database structure. It will be convenient to organize a test environment with a copy of real data and test different index structures there.
Do not create indexes for every column, which is in the query, MySQL does not work that way. Use unique indexes where needed. Always set primary keys.
--